A migração para 400G/800G: Parte I
O planejamento para enfrentar os desafios futuros do data center começa hoje. Explicação do roteiro de Ethernet.
Nos data centers, o terreno está mudando novamente.
Acelerar a adoção de infraestrutura e serviços em nuvem está gerando a necessidade de mais largura de banda, velocidades mais rápidas e desempenho com latência mais baixa. A tecnologia avançada de switches e servidores está forçando mudanças no cabeamento e arquiteturas. Independentemente do mercado ou foco da sua instalação, você precisa considerar as mudanças na sua arquitetura empresarial ou de nuvem que provavelmente serão necessárias para suportar os novos requisitos. Isso significa entender as tendências que impulsionam a adoção de infraestrutura e serviços em nuvem, bem como as tecnologias de infraestrutura emergentes que permitirão que sua organização atenda aos novos requisitos. Aqui estão algumas coisas para pensar enquanto você planeja o futuro.
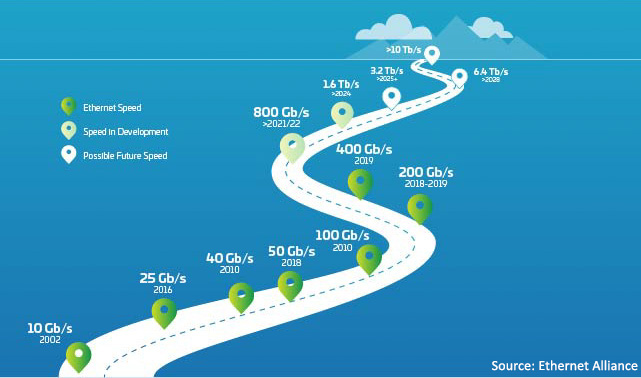
Figura 1: Roteiro de Ethernet
Você quer ler off-line?
Baixe uma versão em PDF deste artigo para ler novamente mais tarde.
Mantenha-se informado!
Inscreva-se no The Enterprise Source e receba atualizações quando novos artigos forem publicados.
Uso global de dados
Obviamente, no centro das mudanças estão as tendências globais que estão reformulando as expectativas e a demanda dos consumidores por comunicações mais rápidas, como:
- Crescimento explosivo no tráfego de mídia social
- Implantação de serviços 5G, possibilitada pela enorme densificação de small cells
- Aceleração de implantações de IoT e IIoT (IoT industrial)
- Uma mudança do trabalho tradicional baseado em escritório para opções remotas
Crescimento de provedores de hiperescala
Globalmente, os verdadeiros data centers de hiperescala podem ser menos de uma dúzia, mas seu impacto na paisagem geral de data center é significativo. De acordo com uma pesquisa recente, somando o mundo todo, um 1,25 bilhão de anos foram passados on-line somente em 2020.1Cerca de 53% desse tráfego passa por uma instalação de hiperescala.2
Parceria em hiperescala com instalações de data center multi-tenant (MTDC/co-localização)
À medida que a demanda por um desempenho de latência mais baixa aumenta, os provedores de hiperescala e de nuvem trabalham para estender sua presença até mais perto do usuário final/dispositivo final. Muitos estão fazendo parceria com MTDC ou data centers de colocalização para localizar seus serviços na chamada "borda" da rede3. Quando a borda está fisicamente próxima, a latência mais baixa e os custos de rede expandem o valor dos novos serviços de baixa latência. Como resultado, o crescimento na área de hiperescala está forçando MTDCs e instalações de co-localização a adaptar suas infraestruturas e arquiteturas para suportar as demandas de escala e tráfego maiores que são mais comuns em data centers de hiperescala. Ao mesmo tempo, esses data centers maiores devem continuar sendo flexíveis para as solicitações dos clientes de conexões cruzadas com acessos do provedor de nuvem.
Redes mesh e spine-leaf
A necessidade de suportar aplicações de baixa latência, alta disponibilidade e largura de banda muito grande dificilmente se limita a data centers de hiperescala e colocalização. Todas as instalações de data center devem agora repensar sua capacidade de lidar com as crescentes demandas dos usuários finais e das partes interessadas. Em resposta, os gerentes de data center estão se movendo rapidamente em direção a redes mesh de fibra densa. A conectividade de qualquer um para qualquer um, os cabos de backbone de maior contagem de fibra e as novas opções de conectividade permitem que as operadoras de rede suportem velocidades de pista cada vez mais altas à medida que se preparam para fazer a transição para 400 Gigabits por segundo4(G).
Habilitar o aprendizado de máquina (ML) e a inteligência artificial (IA)
Além disso, os maiores provedores de data center, impulsionados em parte pela IoT e aplicações de cidades inteligentes, estão recorrendo à IA e ao ML para ajudar a criar e refinar os modelos de dados que alimentam os recursos de computação quase em tempo real na borda. Além de ter o potencial de habilitar um novo mundo de aplicações (pense em carros autônomos comercialmente viáveis), essas tecnologias exigem grandes conjuntos de dados, muitas vezes chamados data lakes, grande poder de computação dentro dos data centers e condutos grandes o suficiente para levar os modelos refinados para a borda quando necessário.5
Sincronizando a mudança para 400G/800G
Não é porque você está operando com 40G ou até mesmo 100G hoje que você deve se deixar enganar por uma falsa sensação de segurança. Se a história da evolução do data center nos ensinou alguma coisa, é que a taxa de mudança, seja em largura de banda, densidade de fibra ou velocidades de pista, acelera exponencialmente. A transição para o 400G está mais perto do que você imagina. Não tem certeza? Some o número de portas de 10G (ou mais rápidas) que você está suportando atualmente e imagine que elas progridem para 100G. Você perceberá que a necessidade de 400G (e além) não está tão longe.
Quando os gerentes de data center olham para o horizonte, os sinais de uma evolução baseada em nuvem estão em todos os lugares.
Mais
servidores virtualizados de alto desempenho
Maior
largura de banda e latência mais baixa
Conexões mais rápidas
entre comutador e servidor
Maior
velocidade de uplink/backbone
Rápida
capacidade de expansão
Na própria nuvem, o hardware está mudando. Várias redes distintas típicas em um data center legado evoluíram para um ambiente mais virtualizado que usa recursos de hardware agrupados e gerenciamento orientado por software. Essa virtualização está gerando a necessidade de rotear o acesso e a atividade do aplicativo da maneira mais rápida possível, forçando muitos gerentes de rede a perguntar: "Como faço para projetar minha infraestrutura para suportar esses aplicativos em nuvem?"
A resposta começa com a habilitação de velocidades mais altas por pista. A progressão de 25 para 50 para 100G ou mais é fundamental para chegar a 400G ou mais, e começou a substituir o caminho de migração tradicional de 1/10G. Mas há muito mais a fazer além de aumentar a velocidade das pistas, muito mais. Temos que aprofundar um pouco.
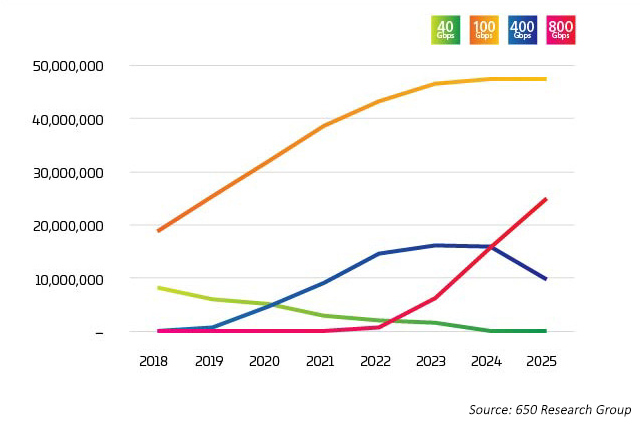
O setor está atingindo um ponto de inflexão. A adoção do 400G se intensificou muito rapidamente, mas em breve espera-se que o 800G comece a crescer ainda mais rápido do que o 400G. Como seria de esperar, não há uma resposta simples para “quem ou o que está orientando a transição para 400G?” Há uma variedade de fatores em jogo, muitos dos quais estão entrelaçados. Novas tecnologias permitem menor custo por bit quando as taxas de pista aumentam. Os dados mais recentes estimam que as taxas de pista de 100G serão combinadas com portas de comutador octal para levar as opções de 800G ao mercado a partir de 2022. No entanto, essas portas estão sendo utilizadas de várias maneiras, conforme ilustrado nos dados da Light Counting6, onde 400G e 800G são divididos principalmente em 4X ou 8X 100G. É essa aplicação de breakout que é o fator inicial dessas novas aplicações ópticas.
Figura 2: Envios de portas Ethernet para data centers
Na rede de dados, a capacidade é uma questão de verificações e equilíbrios entre servidores, comutadores e conectividade. Cada um força o outro a ser mais rápido e mais barato, para acompanhar com eficiência a demanda produzida por conjuntos de dados aumentados, IA e aprendizado de máquina. Durante anos, a tecnologia de comutação foi o principal gargalo. Com a introdução do StrataXGS® Tomahawk® 3 da Broadcom, os gerentes de data center agora podem aumentar as velocidades de comutação e roteamento para 12,8 terabits/s (Tb/s) e reduzir seu custo por porta em 75 por cento. O chip de comutação Tomahawk 4 da Broadcom, com uma largura de banda de 25 Tb/s, fornece ao setor de data center mais capacidade de comutação para ficar à frente das crescentes cargas de trabalho de IA e aprendizado de máquina. Hoje, este chip suporta 64 portas 400G; mas com capacidade de 25,6 Tb/s, a tecnologia de semicondutores está nos levando por um caminho onde, no futuro, poderíamos ver 32 portas 800G em um único chip. 32, coincidentemente, é o número máximo de QSFP-DD ou OSFP (transceptores 800G) que podem ser apresentados em um painel frontal de comutador 1U.
Então, agora, o fator limitante é a capacidade de processamento da CPU. Certo? Errado. No início deste ano, a NVIDIA apresentou seu novo chip Ampere para servidores. Acontece que os processadores usados em jogos são perfeitos para lidar com o treinamento e o processamento baseado em inferência necessários para IA e aprendizado de máquina. De acordo com a NVIDIA, uma máquina com o Ampere pode fazer o trabalho de 120 servidores com tecnologia Intel.
Figura 3: Velocidades de Ethernet
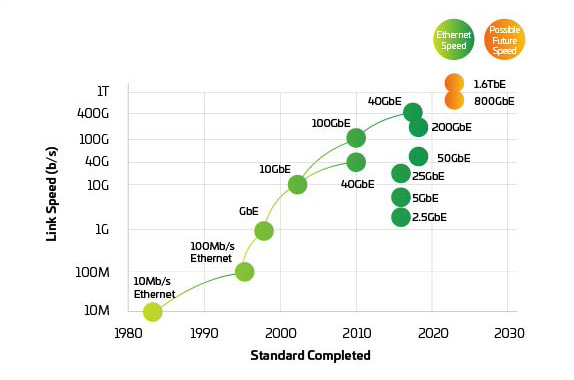
Com comutadores e servidores programados para suportar 400G e 800G no momento em que sejam necessários, a pressão muda para a camada física para manter a rede equilibrada. IEEE 802.3bs, aprovado em 2017, abriu caminho para a Ethernet de 200G e 400G. No entanto, a IEEE acaba de concluir sua avaliação de largura de banda em relação a 800G ou mais. A IEEE iniciou um grupo de estudo para identificar os objetivos para aplicações além de 400G e, dado o tempo necessário para desenvolver e adotar novos padrões, podemos já estar ficando para trás. O setor agora está trabalhando em conjunto, introduzindo 800G e começando a trabalhar em direção a 1.6 T ou mais, melhorando a energia e o custo por bit.
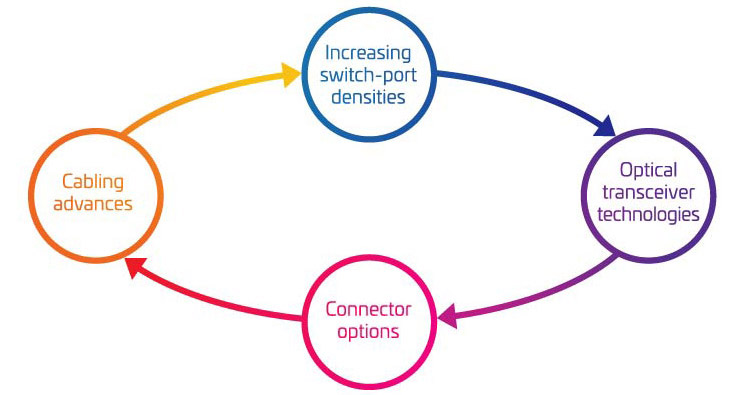
Os quatro pilares da migração 400G/800G
À medida que você começa a considerar as “porcas e parafusos” para apoiar sua migração para o 400G, é fácil ficar sobrecarregado com todas as peças móveis envolvidas. Para ajudá-lo a entender melhor as principais variáveis que precisam ser consideradas, nós as agrupamos em quatro áreas principais:
- Maiores densidades das portas dos comutadores
- Tecnologias de transceptor óptico
- Opções do conector
- Avanços em cabeamento
Juntas, essas quatro áreas representam uma grande parte da sua caixa de ferramentas de migração. Use-as para ajustar sua estratégia de migração e atender às suas necessidades atuais e futuras.
As velocidades de comutação estão aumentando à medida que o serializador/desserializador (SERDES) que fornece a E/S elétrica para a comutação ASIC passa de 10G a 25G e 50G. Espera-se que o SERDES atinja 100G assim que IEEE802.3ck se tornar um padrão ratificado. Os circuitos integrados específicos da aplicação do comutador (ASICs) também estão aumentando a densidade da porta de E/S (também conhecida como radix). Os ASICs de radix mais altos suportam mais conexões de dispositivos de rede, oferecendo o potencial de eliminar comutadores ToR (top-of-rack) de camada. Isso, por sua vez, reduz o número geral de comutadores necessários para uma rede em nuvem. (Um data center com 100.000 servidores pode ser suportado com dois níveis de comutação com um RADIX de 512.) Os ASICs de radix mais altos se traduzem na redução de CAPEX (menos comutadores), OPEX (menos energia necessária para alimentar e resfriar menos comutadores) e em um desempenho de rede melhorado por meio de latências mais baixas.
Figura 4: Efeitos de comutadores Radix mais altos na largura de banda do comutador
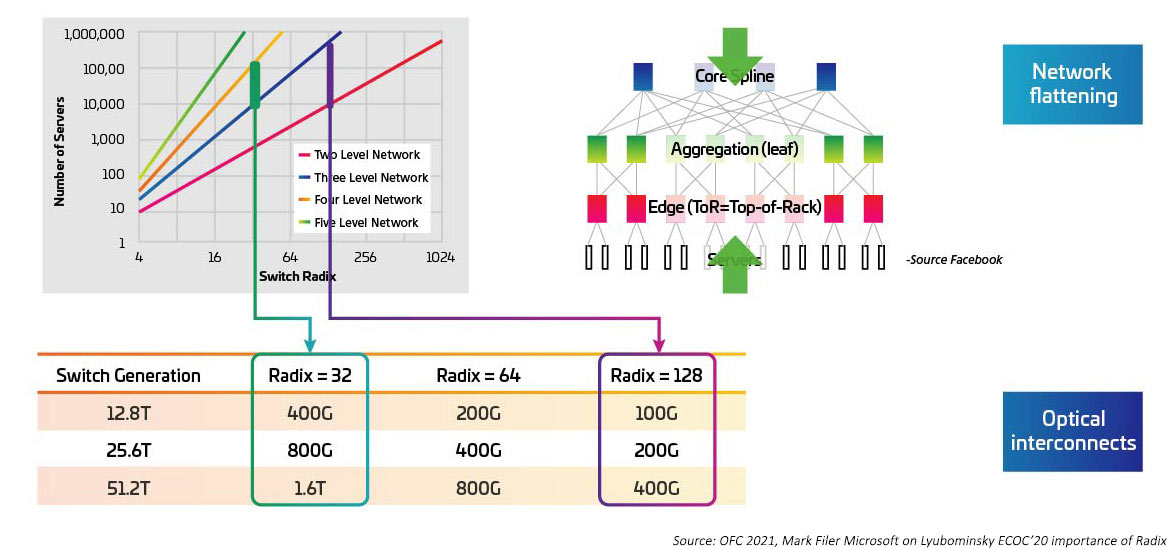
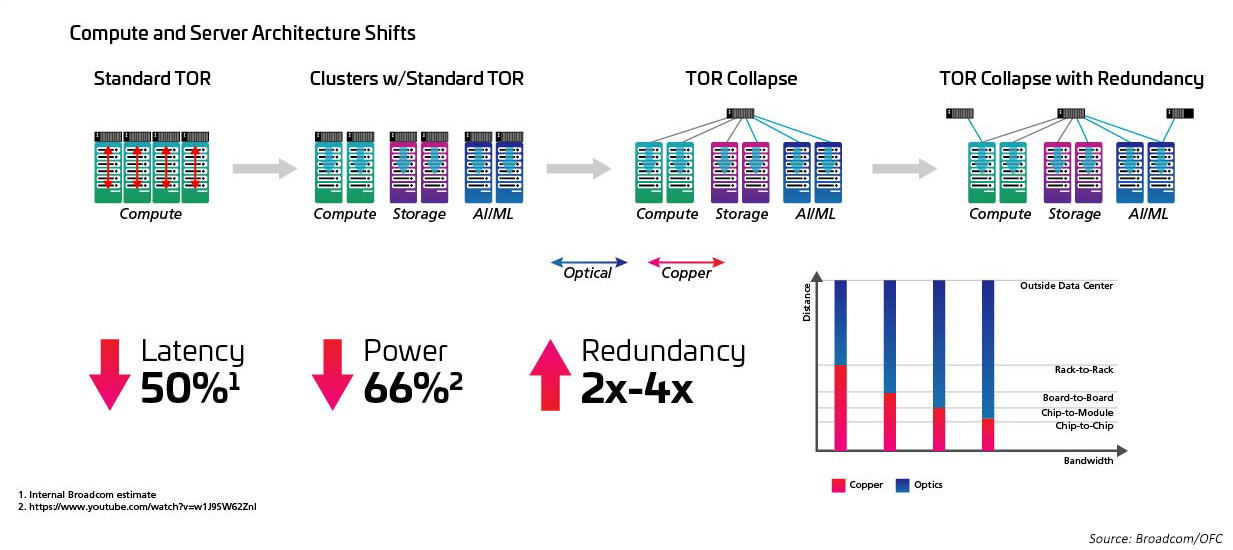
O aumento da velocidade de rádio e de comutação está intimamente relacionado à passagem de uma topologia top-of-rack (ToR) para uma configuração de middle-of-row (MoR) ou ou end-of-row (EoR), e ao benefício que a abordagem de cabeamento estruturado proporciona ao facilitar as muitas conexões entre os servidores em linha e os comutadores MoR/EoR. A capacidade de gerenciar o grande número de anexos de servidor com maior eficiência é necessária para fazer uso de novos comutadores de radix alto. Isso, por sua vez, requer novos módulos ópticos e cabeamento estruturado, como aqueles definidos no padrão IEEE802.3cm. O padrão IEEE802.3cm suporta os benefícios de transceptores conectáveis para uso com aplicações de rede de servidor de alta velocidade em grandes data centers, definindo oito anexos de host para um transceptor QSFP-DD.
Figura 5: Arquiteturas que mudam de ToR para MoR/EoR
Assim como a adoção do fator de forma QSFP28 impulsionou a adoção de 100G, oferecendo alta densidade e menor consumo de energia, o salto para 400G e 800G está sendo habilitado por novos fatores de forma de transceptor. As ópticas SFP, SFP+ ou QSFP+ atuais são suficientes para permitir velocidades de link de 200G. No entanto, fazer o salto para 400G exigirá dobrar a densidade dos transceptores. Não se preocupe.
Os contratos multifonte (MSAs) dos conectáveis dos modelos padrão pequenos (OSFP8) QSFP-Double Density (QSFP-DD7) e Octal (2 vezes um quad) permitem que as redes dobrem o número de conexões de E/S elétricas ao ASIC. Isso não só permite que a adição de mais E/Ss atinja velocidades agregadas mais altas, mas também permite que o número total de conexões de E/S de ASIC alcance a rede.
O modelo padrão do comutador 1U com 32 portas QSFP-DD corresponde a 256 (32x8) E/Ss de ASIC. Dessa forma, podemos criar links de alta velocidade entre comutadores (8*100 ou 800G), mas também podemos manter o número máximo de conexões ao conectar servidores.
Novos formatos de transceptor
O mercado óptico para 400G está sendo impulsionado pelo custo e pelo desempenho à medida que os fabricantes tentam chegar ao ponto ideal dos data centers de hiperescala e escala em nuvem. Em 2017, o CFP8 tornou-se o modelo padrão do módulo 400G de primeira geração a ser usado em roteadores de núcleo e interfaces de cliente de transporte DWDM. O transceptor CFP8 era o tipo de modelo padrão de 400G especificado pelo MSA CFP. As dimensões do módulo são ligeiramente menores do que a CFP2, enquanto a óptica suporta E/S elétrica CDAUI-16 (16x25G NRZ) ou CDAUI-8 (8x50G PAM4). Quanto à densidade de largura de banda, ela suporta, respectivamente, oito vezes e quatro vezes a densidade de largura de banda do transceptor CFP e CFP2.
Os módulos de fator de forma 400G de "segunda geração" apresentam QSFP-DD e OSFP. Os transceptores QSFP-DD são retrocompatíveis com as portas QSFP existentes. Eles se baseiam no sucesso dos módulos ópticos existentes, QSFP+ (40G), QSFP28 (100G) e QSFP56 (200G).
O OSFP, como a óptica QSFP-DD, permite o uso de oito pistas em vez de quatro. Ambos os tipos de módulos suportam 32 portas em uma placa 1RU (comutador). Para suportar a compatibilidade com versões anteriores, o OSFP requer um adaptador OSFP para QSFP.
Figura 6: OSFP versus transceptor QSFP-DD

Esquemas de modulação
Os engenheiros de rede utilizaram por muito tempo a modulação de não retorno a zero (NRZ) para 1G, 10G e 25G, usando a correção direta de erros (FEC) do lado do host para permitir transmissões de longa distância. Para passar de 40G para 100G, a indústria simplesmente se voltou para a paralelização das modulações de 10G/25G NRZ, utilizando também FEC do lado do host para as distâncias mais longas. Quando se trata de atingir velocidades de 200G/400G e mais rápidas, novas soluções são necessárias.
Figura 7: Esquemas de modulação de velocidade mais alta são usados para suportar tecnologias de 50G e 100G
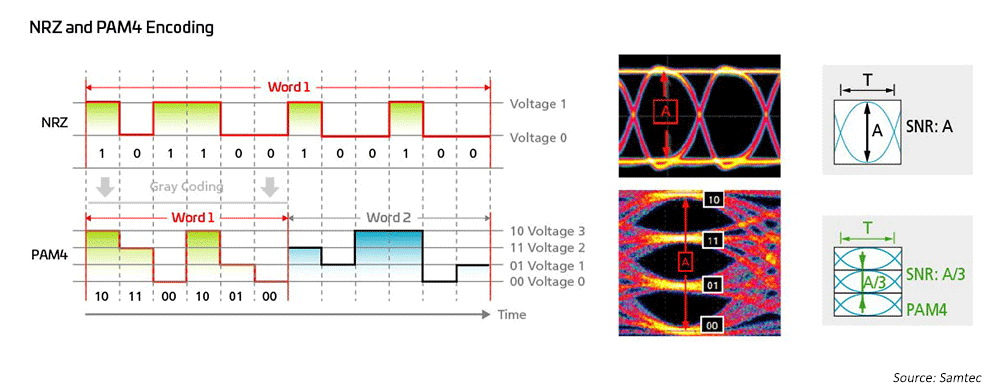
Como resultado, os engenheiros de redes ópticas recorreram à modulação de amplitude de pulso de quatro níveis (PAM4) para concretizar arquiteturas de rede de largura de banda ultra-alta; o PAM4 é a solução atual para 400GPAM4. Isso é baseado em grande medida no IEEE802.3, que concluiu novos padrões Ethernet para taxas de até 400G (802.3bs/cd/cu) para aplicações multimodo (MM) e monomodo (SM). Uma variedade de opções de breakout está disponível para acomodar diversas topologias de rede em data centers de grande escala.
Esquemas de modulação mais complexos implicam a necessidade de uma infraestrutura que possa fornecer melhor perda e atenuação de retorno.
Previsões – OSFP vs. QSFP-DD
Com relação ao OSFP em relação ao QSFP-DD, é muito cedo para dizer que direção setor vai tomar agora; ambos os modelos padrão são suportados pelos principais fornecedores de comutadores de Ethernet para data center e ambos têm grande suporte ao cliente. Talvez a empresa prefira o QSFP-DD como um aprimoramento da óptica atual baseada em QSFP. O OSFP parece estar ampliando o horizonte com a introdução do OSFP-XD, estendendo o número de pistas para 16 de olho nas taxas de pista de 200G no futuro.
Para velocidades de até 100G, o QSFP tornou-se uma solução de referência devido ao seu tamanho, potência e vantagem de custo em comparação com transceptores duplex. O QSFP-DD se baseia nesse sucesso e fornece compatibilidade com versões anteriores, o que permite o uso de transceptores QSFP em um comutador com a nova interface DD.
Olhando para o futuro, muitos acreditam que a pegada 100G QSFP-DD será popular durante muitos anos. A tecnologia OSFP pode ser favorecida para links ópticos DCI ou aqueles que exigem especificamente maior potência e mais E/Ss ópticas. Os proponentes do OSFP preveem transceptores de 1.6 T e, talvez, 3.2 T no futuro.

A óptica co-empacotada (CPOs) fornece um caminho alternativo para 1.6 T e 3.2 T. Mas os CPOs precisarão de um novo ecossistema que possa aproximar a óptica dos ASICs do comutador para atingir as velocidades aumentadas e reduzir o consumo de energia. Esta faixa está sendo desenvolvida no Optical Internetworking Forum (OIF). O OIF está discutindo agora as tecnologias que podem ser mais adequadas para a “próxima taxa”, com muitos defendendo uma duplicação para 200G. Outras opções incluem mais pistas – talvez 32, já que alguns acreditam que mais pistas e taxas de pista mais altas serão eventualmente necessárias para acompanhar a demanda da rede a um custo de rede acessível.
A única previsão segura é que a infraestrutura de cabeamento deve ter a flexibilidade integrada para suportar suas futuras topologias de rede e requisitos de link. Enquanto os astrônomos há muito tempo sustentam que “todos os fótons contam” e os designers de rede buscam reduzir a energia por bit para alguns pJ/Bit9, a conservação em todos os níveis é importante. O cabeamento de alto desempenho ajudará a reduzir a sobrecarga da rede.
Os comutadores estão evoluindo para fornecer mais pistas em velocidades mais altas, reduzindo o custo e a potência das redes. Os módulos octais permitem que esses links adicionais se conectem através do espaço de 32 portas de um comutador 1U. A manutenção do radix mais alto é realizada usando a quebra de linha do módulo óptico.
A variedade de opções de tecnologia de conector fornece mais maneiras de dividir e distribuir a capacidade adicional que os módulos octais fornecem. Os conectores incluem conectores paralelos de 8, 12, 16 e 24 fibras multi-push on (MPO) e conectores LC, SN, MDC e CS de fibra duplex. Veja abaixo para saber mais.
Figura 8: Opções para distribuição de capacidade de módulos octais
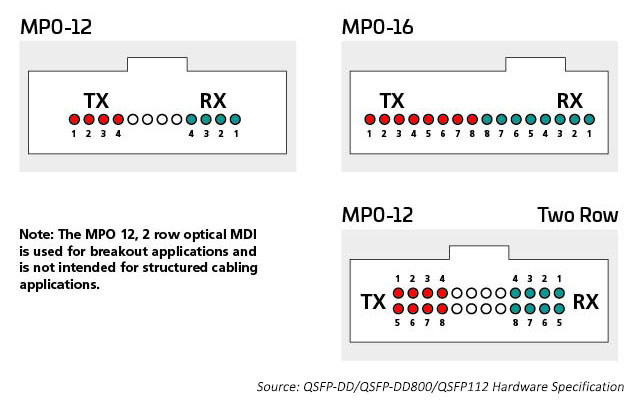
Conector MPO
Até recentemente, o principal método de conexão de comutadores e servidores dentro do data center envolvia cabeamento organizado em torno de 12 ou 24 fibras, usando normalmente conectores MPO. A introdução da tecnologia octal (oito linhas de comutador por porta de comutador) permite que os data centers correspondam ao aumento do número de E/S de ASIC (atualmente 256 por comutador ASIC) com portas ópticas. Isso gera o número máximo de E/Ss disponíveis para conectar servidores ou outros dispositivos.
As E/Ss ópticas usam conectores que são apropriados para o número de pistas ópticas usadas. Um transceptor de 400G pode ter um conector LC duplex simples com uma E/S óptica de 400G, ele também pode ter E/Ss ópticas 4 X 100G que exigem 8 fibras. Os conectores duplex MPO12 ou talvez 4 SN caberão dentro do estojo do transceptor e fornecerão as 8 fibras de que esta aplicação precisa. São necessárias dezesseis fibras para associar às 8 E/Ss elétricas e ópticas, preservando o raio do comutador ASIC. As portas ópticas podem ser monomodo ou multimodo, dependendo da distância que o link foi projetado para suportar.
Por exemplo, a tecnologia multimodo continua fornecendo as taxas de dados ópticos de alta velocidade mais econômicas para links de curto alcance no data center. Os padrões IEEE suportam a tecnologia 400G em um único link (802,3 400G SR4.2), que usa quatro fibras para transmitir e quatro fibras para receber, com cada fibra transportando dois comprimentos de onda. Esse padrão amplia o uso de técnicas de multiplexação por divisão de comprimento de onda bidirecional (BiDi WDM) e foi originalmente projetado para suportar links de switch a switch. Este padrão usa o conector MPO12 e foi o primeiro a otimizar usando OM5 MMF.
A manutenção do raio do switch é importante quando muitos dispositivos, como racks de servidor, precisam ser conectados à rede. O SR8 400G, abordado no padrão IEEE 802.3cm (2020), suporta oito conexões de servidor usando oito fibras para transmitir e oito fibras para receber. Essa aplicação obteve apoio entre as operadoras de nuvem. As arquiteturas MPO-16 estão sendo implantadas para otimizar essa solução.
Os padrões monomodo suportam aplicações de maior alcance (comutação para comutação, por exemplo). IEEE 400G-DR4 suporta alcance de 500 medidores com 8 fibras. Essa aplicação pode ser suportada pelo MPO-12 ou MPO-16. O valor da abordagem de 16 fibras é a flexibilidade adicional; os gerentes de data center podem dividir um circuito de 400G em links gerenciáveis de 50/100G. Por exemplo, uma conexão de 16 fibras no switch pode ser dividida para suportar até oito servidores conectados a 50/100G, ao mesmo tempo em que corresponde à taxa da pista elétrica. Os conectores MPO de 16 fibras são codificados de forma diferente para evitar a conexão com os conectores MPO de 12 fibras.
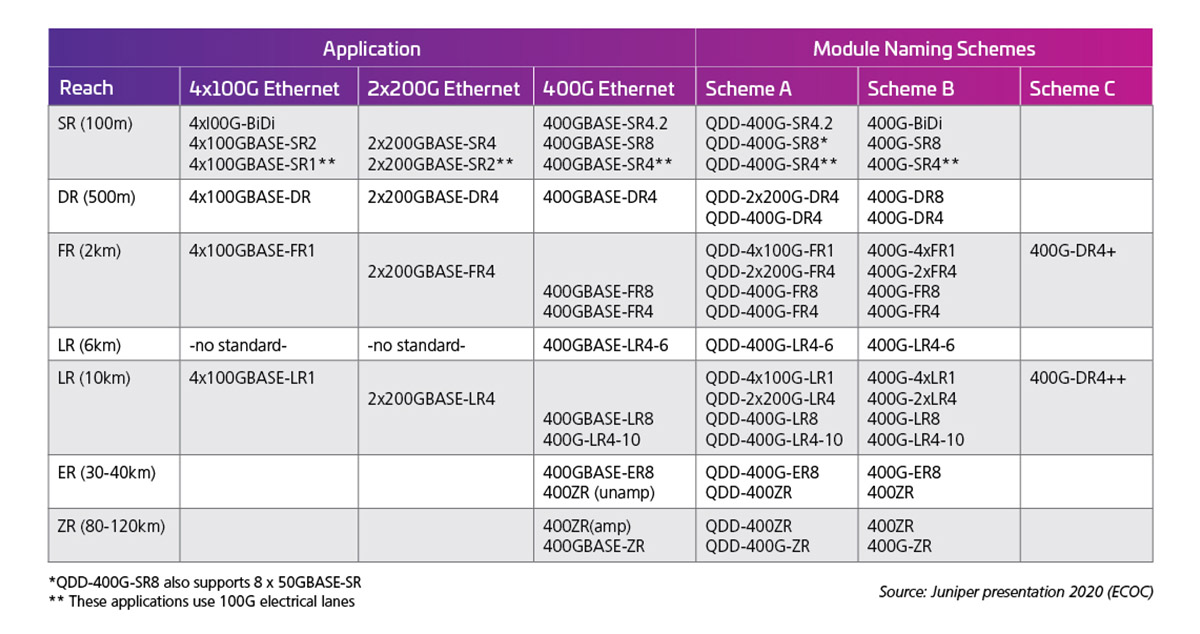
A taxa da pista elétrica determina então os recursos de saída da interface óptica. A Tabela 1 mostra exemplos dos padrões/possibilidades do módulo 400G (50G X 8).
Tabela 1: QSFP-DD com capacidade de 400G com faixas elétricas de 50G
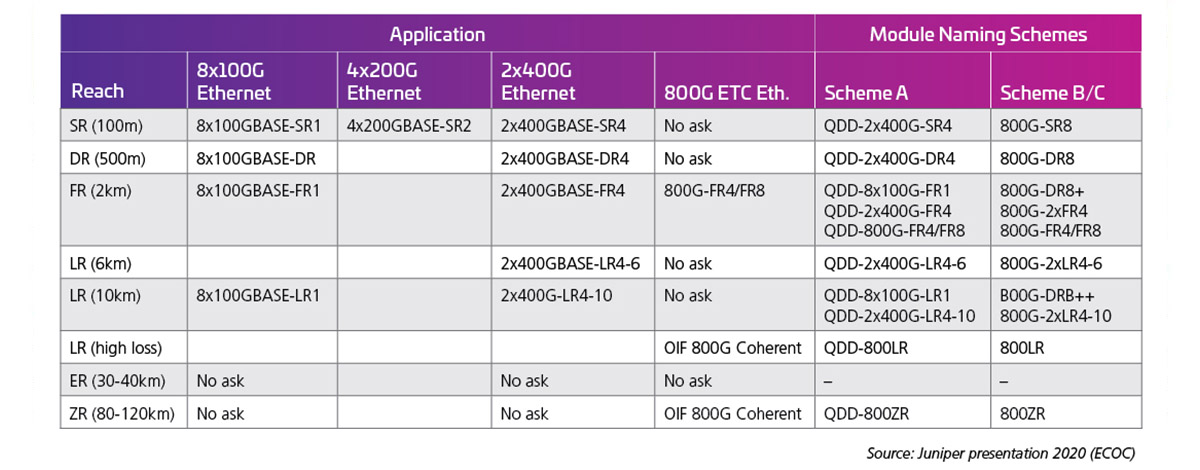
Quando as taxas de faixa são duplicadas para 100G, as seguintes interfaces ópticas se tornam possíveis. No momento da redação, os padrões de taxa de faixa de 100G (802,3 ck) não tinham sido concluídos; no entanto, os primeiros produtos estão sendo lançados e muitas dessas possibilidades estão de fato sendo disponíveis. A Tabela 2, apresentada no ECOC 2020 por J. Maki (Juniper), mostra o interesse inicial da indústria nos módulos 800G.
Tabela 2: QSFP-DD com capacidade de 800G com faixas elétricas de 100G
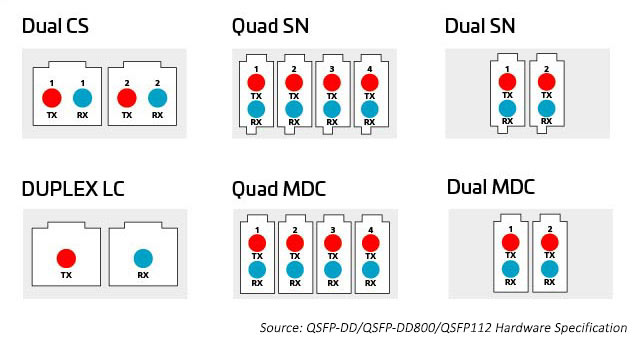
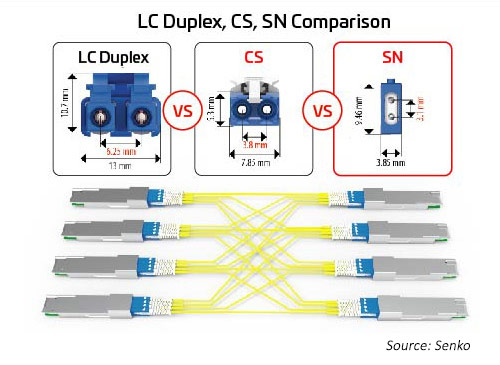
Conectores duplex
À medida que o número de pistas e velocidades de pista aumentam, a divisão das E/Ss ópticas se torna mais atraente. Como mencionado anteriormente, os módulos octais podem suportar opções de conector para 1, 2 4 ou 8 links duplex. Todas essas opções podem ser acomodadas usando um conector MPO; no entanto, essa opção pode não ser tão eficiente quanto conectores duplex separados. Um conector duplex com uma dimensão menor pode ajudar a habilitar essas opções. O SN, um conector de fibra óptica duplex com modelo padrão muito pequeno (VSFF), se encaixa nesta aplicação. Ele incorpora a mesma tecnologia de terminal de 1,25 mm usada anteriormente nos conectores LC. Como resultado, ele oferece o mesmo desempenho óptico e força, mas é direcionado para opções de breakout mais flexíveis para módulos ópticos de alta velocidade. O conector SN pode fornecer quatro conexões duplex a um módulo transceptor octal. As primeiras aplicações para o SN são principalmente para permitir aplicações de breakout de módulo óptico.
Figura 10: Relação de tamanho entre os principais conectores duplex e as aplicações de breakout para migração de 400G/800G
Limites de velocidade do conector?
Os conectores normalmente não ditam a velocidade, a economia sim. As tecnologias ópticas foram inicialmente desenvolvidas e implantadas por provedores de serviços que tinham meios financeiros e demandas de largura de banda para apoiar seu desenvolvimento, bem como os links de longa distância que são mais economicamente conectados usando o menor número de fibras. Atualmente, a maioria dos provedores de serviços prefere a tecnologia de conectores simplex ou duplex emparelhada com protocolos de transporte óptico que usam tecnologias de conector de fibra única, como LC ou SC.
No entanto, essas soluções de longa distância podem ser muito caras, especialmente quando há centenas ou milhares de links e distâncias de link mais curtas para atravessar; ambas as condições são típicas de um data center. Portanto, os data centers geralmente implantam óptica paralela. Como os transceptores paralelos fornecem um custo mais baixo por Gigabit, a conectividade baseada em MPO é uma boa opção em distâncias mais curtas. Assim, as escolhas de conectores atuais não são muito afetadas pela velocidade, mas pelo número de linhas de dados que podem suportar, o espaço que ocupam e o impacto do preço sobre as tecnologias de transceptores e switches.
Na análise final, a gama de transceptores ópticos e conectores ópticos está se expandindo, impulsionada por uma ampla variedade de projetos de rede. Os data centers de hiperescala podem optar por implementar um projeto óptico muito personalizado; considerando a escala desses fatores do mercado, organismos padronizadores e fabricantes geralmente respondem desenvolvendo novos padrões e oportunidades de mercado. Como resultado, o investimento e a expansão levam o setor para novas direções, e os projetos de cabeamento evoluem para suportar esses novos requisitos.
Para saber mais sobre os avanços mais recentes em cabeamento, leia A migração para 400G/800G: Parte II.

Propel™ - a plataforma de fibra de alta velocidade

Soluções para data center corporativo

Soluções
Data center em nuvem e em hiperescala

Soluções
Data centers multi-tenant

Soluções
Data centers de provedores de serviço

Percepções
Fibra multimodo: ficha técnica
Recursos
Biblioteca de migração de alta velocidade

Informações de especificação
MSA DE OSFP

Informações de especificação
MSA DE QSFP-DD
Especificações
Hardware QSFP-DD


À primeira vista, o número de potenciais parceiros de infraestrutura que competem pela sua empresa parece bastante grande. Não faltam provedores dispostos a vender fibra e conectividade para você. Mas, à medida que você olha mais de perto e considera o que é crítico para o sucesso de longo prazo da sua rede, as escolhas começam a diminuir. Isso porque é preciso mais do que fibra e conectividade para alimentar a evolução da sua rede... muito mais. É aí que a CommScope se destaca.
Desempenho comprovado: A história de inovação e desempenho da CommScope abrange mais de 40 anos: nossa fibra monomodo TeraSPEED® estreou três anos antes do primeiro padrão OS2, e nosso multimodo de banda larga pioneiro deu origem ao multimodo OM5. Hoje, nossas soluções de fibra e cobre de ponta a ponta e inteligência AIM suportam suas aplicações mais exigentes com a largura de banda, opções de configuração e desempenho com perda ultrabaixa que você precisa para crescer com confiança.
Agilidade e adaptabilidade: Nosso portfólio modular permite que você responda rápida e facilmente às demandas em constante mudança de sua rede. Conjuntos de cabos pré-terminados monomodo e multimodo, painéis de conexão altamente flexíveis, componentes modulares, conectividade MPO de 8, 12, 16 e 24 fibras, conectores duplex e paralelos de modelo padrão muito pequeno. Com a CommScope, você será sempre rápido, ágil e oportunista.
Pronto para o futuro: À medida que você migra de 100G para 400G, 800G e mais além, nossa plataforma de migração de alta velocidade fornece um caminho claro e amável para densidades de fibra mais altas, velocidades de pista mais rápidas e novas topologias. Recolha camadas de rede sem substituir a infraestrutura de cabeamento, mude para redes de servidor de velocidade mais alta e latência mais baixa conforme suas necessidades evoluem. Uma plataforma robusta e ágil catapulta você para o futuro.
Confiabilidade garantida: Com a garantia de aplicações, a CommScope garante que os links que você projeta hoje atenderão às suas necessidades anos depois. Assumimos esse compromisso com um programa de serviço de ciclo de vida holístico (planejamento, projeto, implementação e operação), uma equipe global de engenheiros de aplicação de campo e a garantia de 25 anos da CommScope.
Disponibilidade global e suporte local: A presença global da CommScope inclui fabricação, distribuição e serviços técnicos locais que abrangem seis continentes e apresentam 20.000 profissionais apaixonados. Estamos à sua disposição, quando e onde você precisar. Nossa rede global de parceiros garante que você tenha os designers, instaladores e integradores certificados para que sua rede continue avançando.





1 Tendências digitais em 2020; thenextweb.com
2 The Golden Age of HyperScale; Data Centre magazine; 30 de novembro de 2020
3 https://attom.tech/wp-content/uploads/2019/07/TIA_Position_Paper_Edge_Data_Centers.pdf
4 https://www.broadcom.com/blog/switch-phy-and-electro-optics-solutions-accelerate-100g-200g-400g-800g-deployments
5 The Datacenter as a Computer Designing Warehouse-Scale Machines Third Edition Luiz André Barroso, Urs Hölzle, and Parthasarathy Ranganathan Google LLC. Morgan & Claypool publishers pg 27
6 LightCounting presentation for ARPA-E conference - outubro de 2019.pdf (energy.gov)
7 http://www.qsfp-dd.com/wp-content/uploads/2021/05/QSFP-DD-Hardware-Rev6.0.pdf
8 https://osfpmsa.org/assets/pdf/OSFP_Module_Specification_Rev3_0.pdf
9 Andy Bechtolsheim, Arista, OFC '21
A mudança para 400Gb está mais perto do que você imagina
Veja a lista dos sinais que apontam para a evolução do data center baseado na nuvem.